Indexing documents stored in database BLOBs or accessed through a file downloader
If your project has documents (PDF, DOCX etc) that are stored in database BLOB objects or on the filesystem, then a question that often arises is 'how do I index them?'.
Developers tend to first think that they need the indexer to access the BLOB content directly, but it's helpful to think of the indexer as a web browser. When you see the indexer as a browser, you recognize that the most straightforward approach is to index the same URLs that your visitors use to access the documents (eg. https://host/docs/1 or https://host/documentviewer.aspx?id=1),
It's uncommon, but if all documents in the database/filesystem already have HTML links from pages that are crawled by the indexer, then the documents should automatically be indexed. Let's assume this is not the case however, this tutorial shows how to approach this problem.
There are two approaches (the second one is most popular);
Approach 1: Add documents to the index programmatically
You can add/index URLs by adding them programmatically. This is simple, but does require a context with-in which to run, such as a console or web application. Adding URLs to the index incrementally is explained here, and it is suggested that you iterate through the documents in the database, calling AddDocument for each. Note that adding a document that is already in the index will not duplicate it, just update it.
Approach 2: Create an invisible URL list page and crawl it
By creating a page holding links to all the document download URLs, you provide the crawler with a route to all documents.
Load/create your web project where you will create the list page.
Create a new page/view
You need to iterate the document records in the DB (or filesystem) and list them in the HTML. The page when rendered as HTML should follow this structure:
<html>
<head>
<meta name="ROBOTS" CONTENT="NOINDEX"/>
</head>
<body>
<!--
href="http://host/mydocs/1234"
href="http://host/mydocs/1235"
-->
</body>
</html>
The meta tag prevents the list page from being listed as a search result.
Open the Index Manager Tool and enter the path to your index directory.
The Index Manager Tool can be found under the Start Menu;
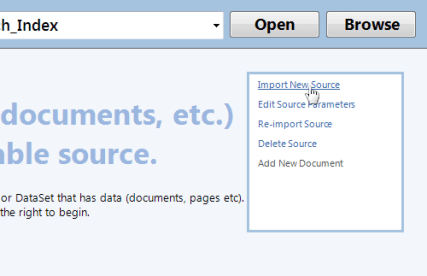
Select 'Import New Source', for the Start URL use the URL of the list page created in the step above & click 'Import'.
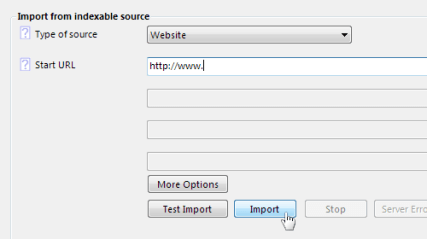
If an error reports the page cannot be read, please check the URL or consult the user guide for help.
Once the import is complete close the Import window, select 'Optimize' and click 'Start Optimize'.