I would like to write about the craftsmanship of coding, and how problems can be made trivial with the right approach, or horrible with the wrong approach.
One example that comes to mind is from the ‘Not in Dictionary’ textbox in our Win Forms and WPF versions of the RapidSpell spell checker.
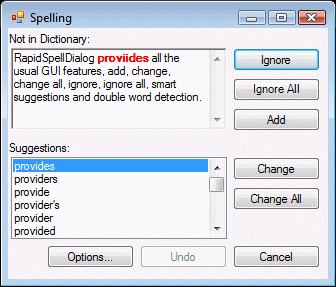
This example is, I feel, ideal for discussion because the problem is easily understandable and the difference between the best and worst approach is distinct.
The dialog has a RichTextBox (called notInDictionary_RTB) and per the screenshot, the misspelled red word “proviides” can be clicked and corrected by the user. Any changes to the word go back to the original field when “Change” is clicked. Changes can also be made with the suggestion list but that’s not relevant here.
The problem
The spell checker wants to know from the dialog what the corrected text is, it doesn’t want the entire contextual sentence from the textbox (for reasons not important here): so how do you extract the correction from the content of the ‘Not in Dictionary’ RichTextBox?
For example, if;
Initially before correction:
notInDictionary_RTB.Text == “RapidSpellDialog proviides all the usual…”
Finally after correction:
notInDictionary_RTB.Text == “RapidSpellDialog provides all the usual…”
So the problem is, how do you return ‘provides’ when the “Change” button is clicked?
The not-so-good approach
You might think, ‘well just grab the red text’, but that is fraught with other pitfalls that aren’t related to coding elegance (such as what if the user pastes formatted text over correction and changes its color).
The not-so-good approach, and the one that is probably a developer’s first thought is to record the start and end character indexes of the text where the error is, 17 and 26.
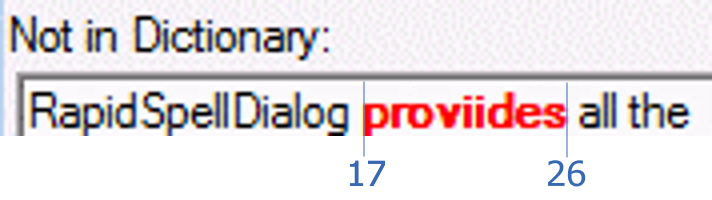
On the face of it, this seems reasonable, because now you can use Substring to pull out the red word when needed. However it becomes tricky to track where the end of the word is as the text changes. For example, if the user deletes the extra ‘i’ in the red word (‘proviides’), then we need to know that the word now ends at index 25, not 26. Similarly if characters are added, or pasted in, the ending index will change.
So this might lead us down the path of using event handlers to track what the user is doing, so we can adjust the ending index (if they use delete or type characters) – yikes! Something that seemed simple is now blowing up with a myriad of potential mistakes waiting to be made.

Step back
Let’s reconsider the problem for a moment, our idea to use event handlers to track the changes to the red word is suitable (if it could be coded perfectly) for not only the problem at hand (where only one part of the text can be edited), but more generally to problems where the text after the red word is allowed to change. In other words, this approach would also work if all the text after the red word was deleted or changed or added to. That feels wrong, because we’re not using all the characteristics of the situation we’re dealing with.
In other words we’re not using a constraint of the system that we’re working with, namely; only one part of the text can be changed. Our proposed solution is doing more work than needed because we’ve neglected to ‘encode’ that the text after the red word is static.
Better solution
Ok, if the text after the red word is not going to change, maybe we can measure the end index of the red word relative to the end of the text (119 characters). This value (119) will be true initially and after the text is corrected.
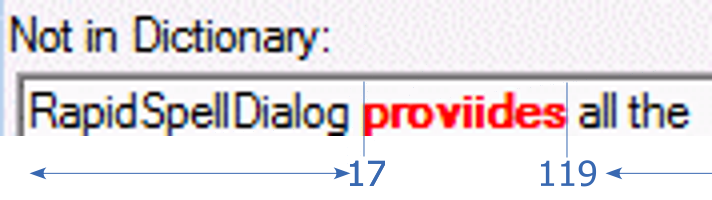
Which means that now to pluck out the corrected word, we only need to work based on the start and end points of the text.
String correction = notInDictionary_RTB.Text.Substring(17, notInDictionary_RTB.Text.Length – 119 - 17)
For illustration I’ve used the actual values rather than variables.
Conclusion
In this example we were able to achieve a more elegant solution by identifying and using the constraints inherent in what we were working with. There are other similar examples I’ve seen where not doing this has caused code to be slow and inefficient (because quite simply the code would have been able to do more than was required of it).
I hope to write more articles with examples of elegant code. For me the enjoyment of software development is the craftsmanship, if not at the method or class level then in the architecture of the system. We can all improve our craft and learn from other’s perspectives.

- Remote debug .NET applications over the internet with Visual Studio - November 14, 2016
- Craft and elegance in programming - May 19, 2016
- Bluetooth Low Energy in Windows 10: Troubleshooting Capabilities - August 31, 2015